定义
在图形界面上看、想、点、打字、拖拽并完成任务的智能体。 它通过“观察屏幕状态→规划→执行操作→再观察→纠错”的闭环, 在桌面应用、网页、移动端 App 等界面中自主操作。
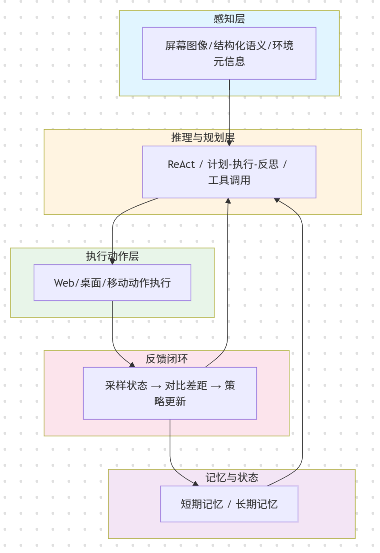
典型体系结构
发展历史:
- 最早是基于规则和脚本的自动化;
- 2010s开始的由于深度学习技术的发展,计算学习用户交互轨迹;
- 2020s后,由于MLLMs的发展,给GUI agent带来了革命性的进展。
paper list:
https://github.com/OSU-NLP-Group/GUI-Agents-Paper-List/
https://github.com/showlab/Awesome-GUI-Agent
https://github.com/slavakurilyak/awesome-ai-agents
通用LVLMs与专用于GUI agent的LVLMs
| 两者区别 | 能力 | 训练数据 | 输出接口 |
|---|---|---|---|
| 通用LVLMs | “能看懂图”的通用聊天型LVLM 坐标/动作是附带能力 | 通用图文对齐 | 需要用提示词告诉他输出坐标,受格式和缩放影响 |
| 专用于GUI agent的LVLMs | “能看懂并去点”的代理型LVLM, 训练与接口都围绕可执行的GUI交互优化 | 大量使用屏幕截图、UI布局、流程轨迹、合成交互数据等训练 | 直接输出动作click(x,y) 相对“用提示让模型说出坐标”,专门有一个负责输出几何量的预测分支,还能给置信度。 |
| 分类 | 举例 | 介绍 | 能力侧重 | 出处 |
|---|---|---|---|---|
| 专用于GUI agent的LVLMs | CogAgent 开源视觉语言模型 | 1. 支持1120*1120的超高分辨率图像输入和对话式问答 2. 跨平台泛化能力 3. 首个专门为GUI理解设计的LVLM | 1. 界面元素识别和语义对齐 2. 元素级定位 3. GUI任务分解和步骤规划 4. 结合文本信息,候选元素列表,提升语义对齐与命中率 | CogAgent (Hong et al., 2023) https://github.com/zai-org/CogVLM https://arxiv.org/abs/2312.08914 清华大学、智谱AI,完全开源 |
| Fuyu-8B | 1. 通用多模态大模型 2. 重点是理解和问答 | 1. 理解内容,尤其是文本密集和结构化视觉(表格、流程图等) 2. 擅长解释页面上写了什么,图标表达了什么 | Fuyu (Bavishi et al., 2023) https://www.adept.ai/blog/fuyu-8b Adept AI完全开源 | |
| 通用LVLMs | LLaVA系列(开源)、Qwen-VL系列(开源)、GPT-4V/GPT-4o(闭源)、Claude Vision系列 (Opus/Sonnet)(闭源)、Gemini(闭源) |