背景:现有GUI agent都是通过提取的结构化数据(html等)与环境交互。
研究方法:纯视觉方案(仅依赖截图)的SeekClick。
关键挑战:GUI grounding(接地):根据指令准确定位屏幕元素的能力。
提出:通过基础预训练来增强SeeClick,并设计一种自动化图形界面用户基础数据管理的方法。创建跨平台,首创的,真实的,GUI grouding benchmark。
结论:通过预训练后,SeekClick在不同基线上展示了ScreenSpot的显著改进。
Introduction
- GUI agent现在的发展:Siri和Copilot(GPT-4的发展)
- 依赖结构化文本的限制:
- 不可访问;
- 冗长导致llm的低效上下文,还会忽略布局等信息;
- 多结构文本需要对特定任务做特定处理。
- 介绍SeekClick,基于LVLMs(Large Vision-Language Models)。引出挑战:GUI grounding,根据指令准确定位屏幕元素的能力。通过预训练策略增强了LVLM。设计了一种方法来获取基础数据。SeeClick使用上述精心策划的数据集对LVLM进行持续预训练,使其能够在各种图形界面环境中准确定位文本、小部件和图标等元素。
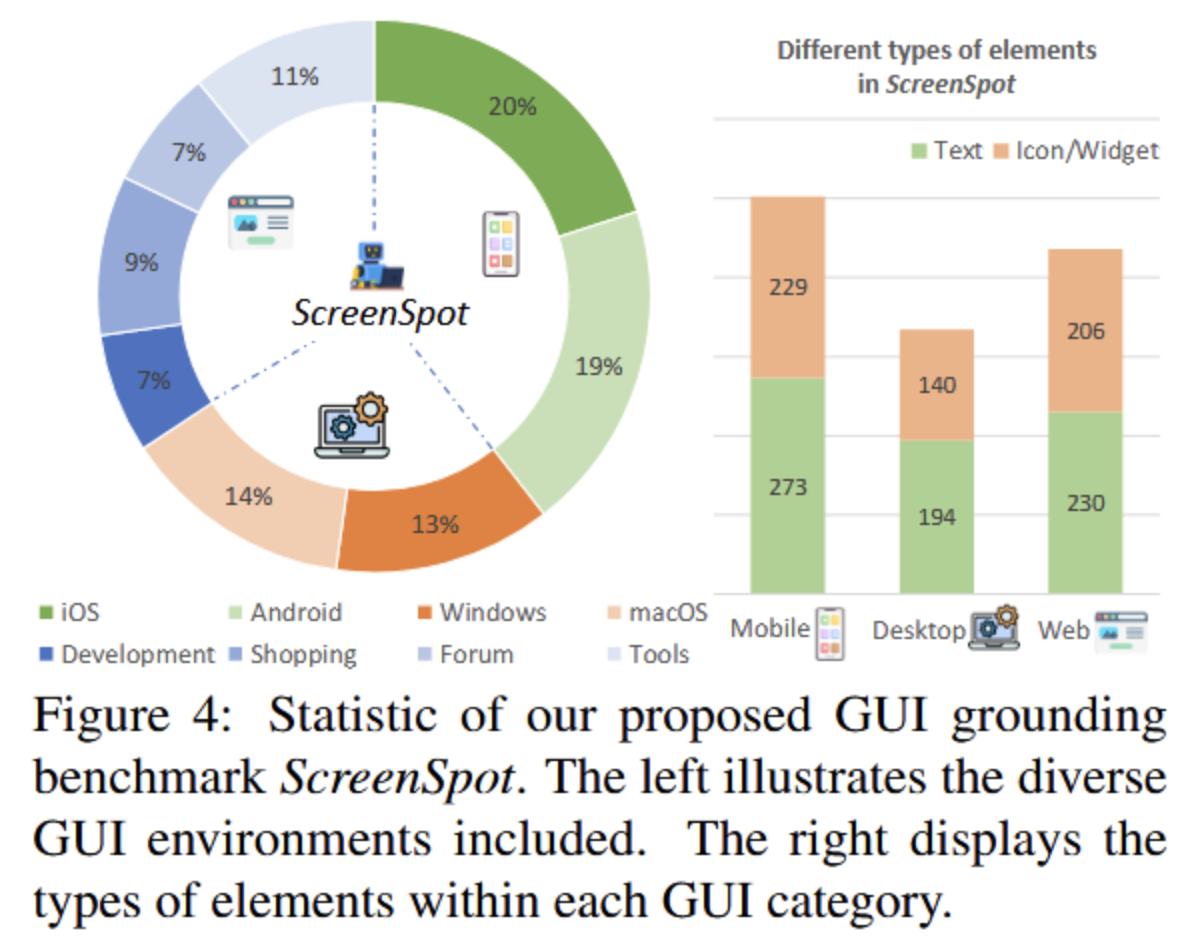
- 介绍SreenSpot。ScreenSpot包含来自iOS、Android、macOS、Windows和网页的600多个屏幕截图和1200条指令,特别包括基于文本的元素以及各种小部件和图标。评估结果证实了SeeClick相对于当前LVLM的优越性,验证了图形用户界面接地预训练的有效性。
- SeeClick超越了强大的视觉基线Pix2Act,同时仅利用了0.3%的训练数据。此外,这三个基准的实验结果一致支持我们的发现,即图形用户界面基础的改善与增强的代理任务性能直接相关。
- 主要贡献有四点:
- SeekClick
- 探索GUI grounding,通过提出的预训练策略增强SeekClick
- 创建benchmark ScreenSpot
- GUI grounding能力是提高下游代理任务性能的管理
Related work
第一段:
早期研究:
- 受限场景下的自动化,web自动化和移动自动化
- 依赖结构化数据
LLM驱动的范式转变
- 利用LLM的规划与推理能力,将GUI交互转化成文本理解+动作生成流程。
- 工作贡献:
- Web任务:WebGUM、AgentGPT
- 跨平台:CogAgent、Mind2Web
- 关键依赖:
- 输入:HTML、DOM、Android VH等结构化文本
- 输出:基于文本标签的动作(如点击
<button id> =”submit”)
第二段(LVLMs):
- 最近的研究在于构建LVLM,通过connecting layers将视觉编码器(vision encoders)与LLM集成,集成LLM的语言和推理能力。
- 很多研究专注于定位(grounding),提供响应的时候提供边界框。但这些都针对的自然图像。
Approach(方法)
GUI grounding for LVLMs
- 如何训练LVLM进行语言生成。
- 给定截图s和元素集合。Xi表示第i个元素的文本描述,Yi表示元素的位置(边界框或点)。LVLM基于s和X,来预测元素Y的位置。
- LVLM生成的是语言格式,怎么来预测数字坐标?
- 之前的研究把图片分成1000个bins,然后创建一个1000token词汇表来表示x和y的坐标。
- 我们采用LVLM中更直观的方式,将数值视为自然语言,无需额外标记、预处理或后处理。
- 例子:一个截图和一个指令描述“查看Jony J的新专辑”,构造了一个查询prompt:“在UI中,我想做<指令>,应该点哪里”。
- 然后计算模型输出和ground truth(click(0.49, 0.40))之间的cross-entropy loss,交叉熵损失,来优化LVLM。
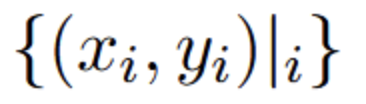
Data Construction(数据建设)
通过三个数据集合训练SeekClick
- Web数据
- 从Common Crawl库收集30万个网页,作为Web UI训练数据。每个网页收集两种数据:1)显示可见文本内容的元素;2)具有title属性的元素(悬停时能显示文本)。
- 两个任务,%% 一个是基于s和x预测坐标y %%,还有基于s和坐标y预测文本描述x。
- Mobile数据分三种类型
- widget captioning(小部件字幕,比如播放按钮上的描述“播放音乐”)、mobile UI grounding、mobile UI summarization
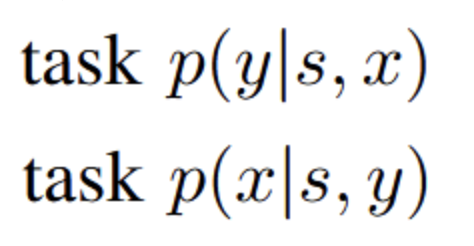
Training Details
- 在QWen-VL(Bai等人,2023)的基础上预训练,构建了SeekClick。QWEN-VL本身具有接地能力和448*448的分辨率。
- 在构建的数据集上训练QWen-VL有10k steps(around 1 epoch),来获得SeekClick。
- 应用了LoRA去微调visual encoder和LLM。细节在附录A中。
ScreenSpot: A Grounding Benchmark
- 早期的LVLM能力受限所以关注有限,缺乏研究,主要是2017年的,Android dataset。
- 填补研究空白,引入ScreenSpot。
- 跨平台的:移动(iOS、Android);桌面(macOS、Windows)和Web。
- 图标/小工具:每个GUI中都有大量的图标和小部件。
- ScreenSpot确保样本新颖且不包含在现有的训练资源中。
Exprements
大体分为三部分:
- VLM和我们的SeekClick的定位能力。
- 然后SeekClick适应mobile&web的代理任务,分析高级定位能力和下游任务性能之间的相关性
- 探索了基于纯视觉的GUI agent的潜力。
GUI Grounding on ScreenSpot
Compared LVLMs & Evaluation
- 两种LVLM:
- 能执行对话、识别和定位等通用任务的LVLM:MiniGPT-v2(Chen等人,2023 a)、Qwen-BL(Bai等人,2023年)和GPT-4V
- 最近发布的专门为GUI任务设计的LVLM:Fuyu(Bavishi等人,2023年)和CogAgent(Hong等人,2023年)
- 以点击准确度作为指标,指标定义为模型预测位置落在真实元素边界框中的测试样本的比例。
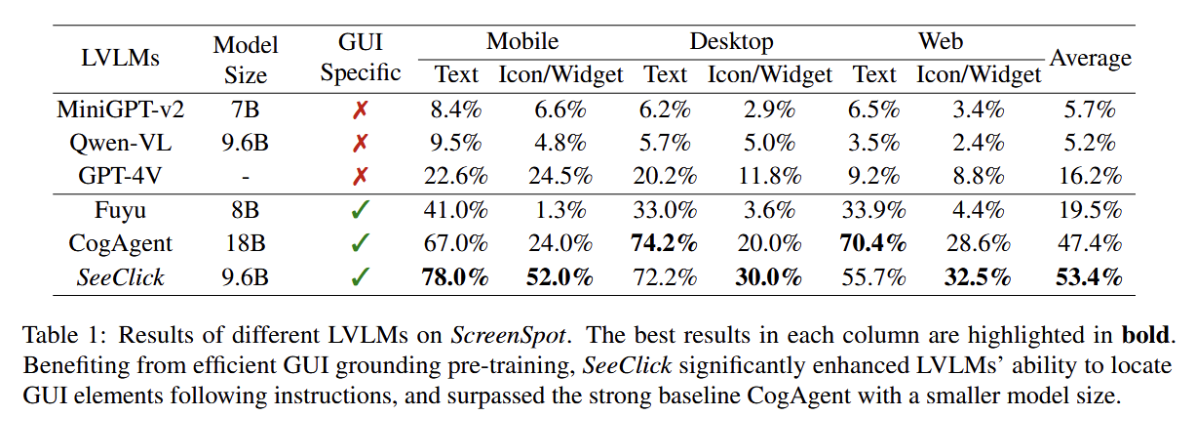
- 结果:每一列中最好的结果加粗表示。
- SeekClick参数量比CogAgent少
- SeekClick在Desktop和Web表现比CogAgent差一点,可能是分辨率较低和训练数据小得多。
- 所有模型都难以定位Icon/Widget。
Visual GUI Agent Tasks
- MiniWob
- 数据准备:
- MiniWob数据缺乏截图,先通过LLM为每个任务生成50个成功轨迹(?),创建一个仅含2.8k个样本的小型训练集。
- 对比基线:
- WebGUM(SOTA):html+截图的混合方法,当时最先进的离线训练模型
- Pix2Act(视觉SOTA):之前的纯视觉方法,但需要大量训练数据
- Qwen-VL(LVLM基线):与seekclick底层模型相同的版本,但未经过GUI定位训练
- 实验结果:
- SeekClick仅用0.3%的Pix2Act训练数据,就超越Pix2Act
- 同等数据量下,SeekClick还是超过了WebGUM
- SeekClick比基线模型QWen-VL高出近20%,证明了GUI定位预训练是提升性能的关键
- 数据准备:
- AITW
- AITW是Android自动化数据集,Android in the wild,来评估智能手机环境中的SeekClick。每个样本包含一条指令和一条带有截图的动作轨迹(?)介绍AITW。
- 提出一个问题:
- 现有的训练-测试划分有显著的过拟合风险,导致实验结果不能反映代理在真实世界的泛化能力。导致SeekClick的性能和CogAgent相当。
- AITW数据集的问题?,同一条指令的不同变体会同时出现在训练集和测试集中,导致模型可能只是记忆了某些指令的步骤。
- 解决方案:
- 以指令为单位重新划分训练集/验证集/测试集。
- 从AITW的5个子集中分别选择545/688/306/700/700条指令,并为每条指令仅保留一个标注片段。这些指令的80%用于训练,剩余20%用于测试,并从原始数据中额外选择5*100个片段构成验证集。
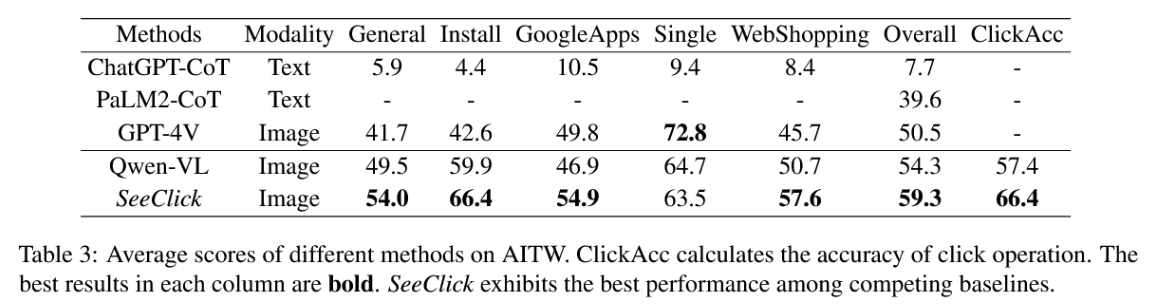
- 结果:SeeClick在基于API的LLM和经过训练的LVLM中实现了最好的平均性能。SeeClick的点击准确性比Qwen-BL提高了9%。
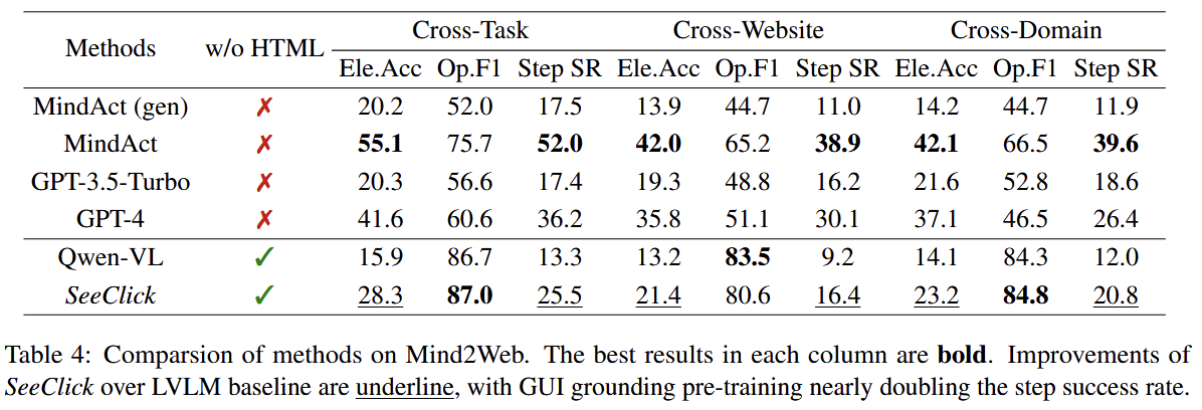
- Mind2Web
- Mind2Web是从137个真实网站收集来的2000多个开放性任务。
- 方法:
- 传统是代理从html结构中选择可操作的元素;SeekClick首次尝试仅以来截图+点击坐标,不看html。
- 元素准确率(Ele.Acc),点击精度(Op.F1),步骤成功率(Step SR)
- 结果:
- SeekClick在多维度(操作准确率、点击精度、步骤成功率)均显著优于QWen-VL
- 下划线是SeekClick over LVLM的部分,几乎是翻倍的。
- Grounding and Agent Performance
- 分析了几个ScreenSpot上的几个SeekClick的检查点和三个下游任务的平均得分改进。
- 结果:
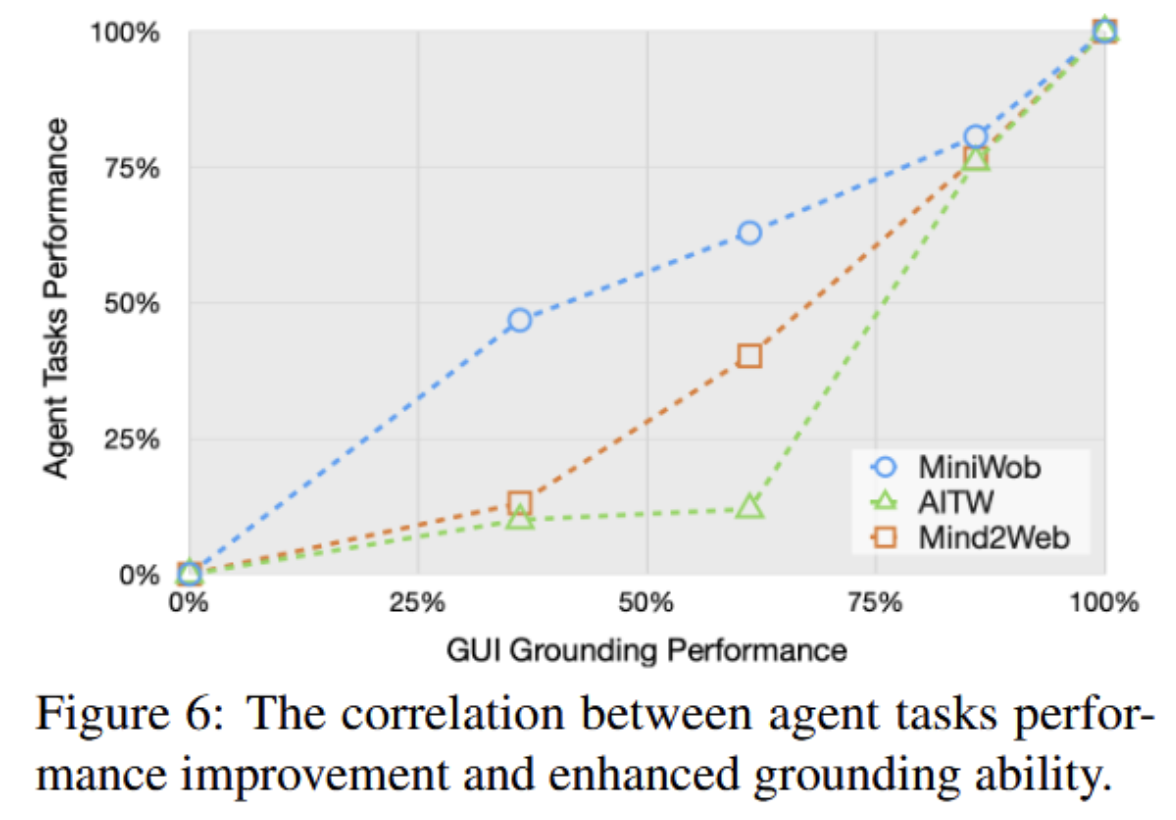
- agent tasks的表现也会随着GUI Grounding的表现提升而提升
- SeekClick as Unified GUI Agent(Unified统一的)
- 联合训练SeekClick处理所有三类任务,验证其统一模型(?)的能力
- 结果:
- 表现略有下降,说明三类GUI差异大,统一模型存在挑战
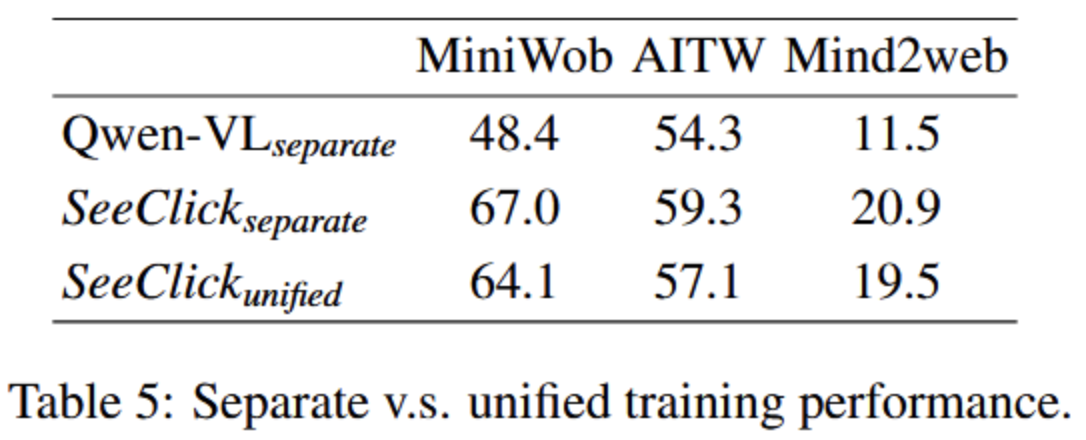
- 但是从这个表看,仍然是优秀的
Conclusion
- 提出纯视觉方案的GUI agent,名为SeekClick
- 关键挑战:GUI grounding
- 解决方案:提出了GUI Grounding预训练机制
- 评估与数据集:创建ScreenSpot的数据集,跨平台,用来测试GUI Grounding
- 结果:
- ScreenSpot上,SeekClick明显优于现有LVLM
- 在三个不同的GUI自动化任务中表现出色,说明GUI Grounding的优秀表现可提升下游自动化任务的性能。
Limitations
- 当前的SeekClick目前只支持click和typing,点击和输入,不支持拖拽(dragging)或双击(double-clicking)等复杂操作。
- 当前开源LVLM的能力有限,如果要在移动端和桌面端完成多步骤任务,还需要专门的数据来训练模型,不能完全依赖通用模型。
A Details of SeekClick Pre-training
A.1 Pre-training Tasks
- 训练任务两大类:
- GUI grounding:定位
- text_2_point:给出对应UI元素的中心点坐标(x, y)
- text_2_bbox:bounding box边界框,给出上下左右。
- GUI 文本生成:根据位置,反推出对应的文字
- point_2_text
- bbox_2_text
- GUI grounding:定位
- 数据表示:
- 坐标都是归一化数值,在[0,1]区间内的浮点数,保留两位小数,表示相对于整个图片的宽和高的比例。
- 例如,(0.32, 0.77) 表示在图片宽度 32% 的地方,和高度 77% 的地方。
A.2 Training Configurations
- 开源多模态大模型QWen-VL-Chat作为基础,进行continual pre-training。
- 解锁视觉编码器visual encoder的梯度?
- 使用LoRA做微调
- 采用AdamW作为优化器,并使用一个Cosine anneal调度器,其init学习率为3e-5,全局批量大小为64。所有训练需要在8个NVIDIA A100图形处理器上进行约24小时。
B ScreenSpot Annotation & Evaluation
B.1 Human Annotation
- 4位有经验的标注员,用 Makesense工具给截图中常用的可点击元素打框;为这些被标注的元素写英文的操作指令。
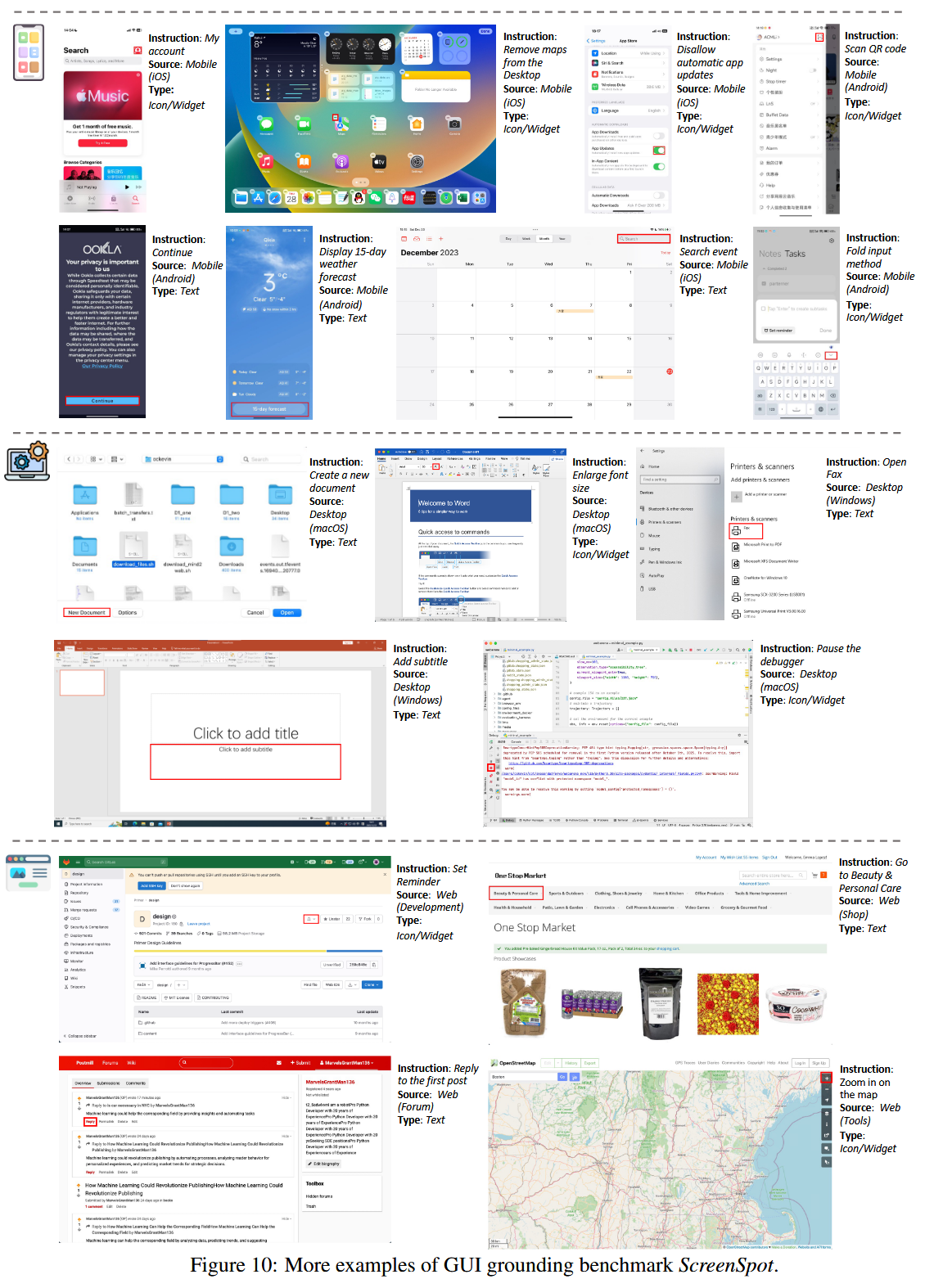
B.2 Sample Showcase
- 图10给了很多例子
B.3 Evaluation Detail
- 对比了主流的多模态模型CogAgent、GPT-4V
- CogAgent推荐的prompt是
“What steps do I need to take to <instruction>? (with grounding)” - GPT-4V,输入指令,要求他输出对应的位置
- CogAgent推荐的prompt是
- 比较他们的输出位置坐标和真实值之间的误差
- SeekClick的评估选择了使用中心点,而不是边界框,因为这个表现略好点
B.4 SeekClick Case Study & Error Analysis
分析错误,发现即使是预测错误,预测点也很靠近真实目标,说明模型能大致识别出目标,只是精度需要提升。 ![[Pasted image 20251021165942.png]]
Downstream Agent Tasks
C.1 Formulation of SeekClick as Visual GUI Agent
- 动作:点击、输入文本、选择、滑动屏幕、返回上一步、返回主页、回车提交
- agent公式:
- 根据截图和之前步操作,预测下一步

C.2 MiniWob
C.3 AITW
- 原来的5个子集General、Install、GoogleApps、Single、WebShopping,划分的不好,有过拟合风险
- 新的训练/验证/测试划分策略
C.4 Mind2Web
- 面向真实网页任务的通用智能体数据集
- 做了哪些改动:
- 原来用于文本,输入仅为html,为了支持视觉模型,从原始网页dump中提取了截图和坐标元素的框
- 原始html的截图很大,处理太复杂,就裁剪了截图,仅保留1920*1080的窗口