introduction
- 第一段:GUI agents的定义,与LLM的关系
- 第二段:参考人类感知数字世界的方式,GUI agent需要做的事,即感知+操作。
- 对于感知,当前agent大多依赖于阅读html和ally tree,随着MLLM的发展,视觉感知变得可行。
- a11y树是一种紧凑但信息丰富的表示,旨在用于辅助技术,以方便残疾人
- 对于操作,当前agent大多是通过选择html元素或labeled bounding boxes来操作,而不是基于图形界面进行像素级操作。
- 补充说了获取html元素或labeled bounding boxes需要文本的输入和用于检测的单独模型。
- 对于感知,当前agent大多依赖于阅读html和ally tree,随着MLLM的发展,视觉感知变得可行。
- 第三段:当前方案的局限性。
- 基于文本的表示是嘈杂、不完整的。(相比之下,视觉输入只包含和用户相关的信息)
- 解析html编码输入增加了延迟和推理成本,消耗token数比视觉编码多出10倍。(补充说了获取ally tree本身就很耗时,损害用户体验和实用性)
- 第四段:我们的工作关注的是:只有视觉感知和像素级操作的GUI agent能做到什么程序。
- 再去介绍一下前人在这个方向上的尝试和瓶颈。grounding:(M)LLM生成的文本怎么映射到GUI上的精确位置。
- GUI agent grounding model的要求: 。
- 高准确性:grounding错误会整个任务失败
- 高概括性:应该是跨平台通用的
- 高灵活性:应该在不同的MLLM中即插即用,而不是与某个模型紧密耦合
- 现在的GUI agent都不能满足以上三个要求。
- 第五段:介绍这项工作的主要贡献,做了那些事情(3方面)。
- 论证+案例,结果是提出一个通用框架SeeAct-V,基于此框架构建的GUI agent,完全以视觉感知+像素级操作。
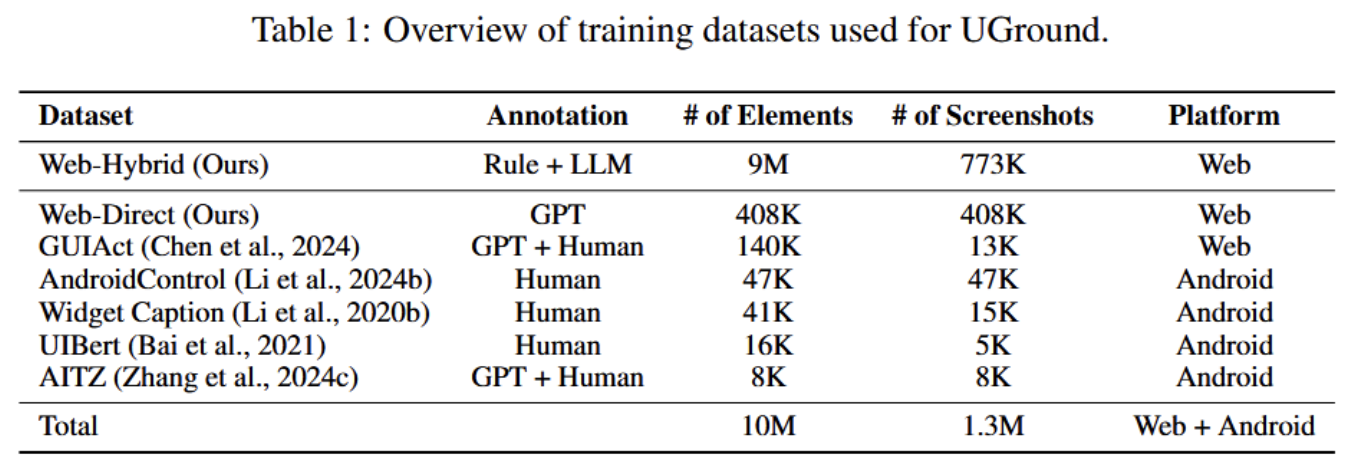
- 一个简单的recipe,包含了网络数据和轻微调整后的[[LLaVA]]架构。使用整个recipe,构建并发布了迄今为止最大的GUI视觉基础数据集,包含了1000万个GUI元素和引用,超过130万个GUI截图。在这个数据集上训练和发布了通用视觉基础模型UGround。
- 对GUI agent进行全面的评估和总结一下结果。
- 评估涵盖6大基准测试(3平台*3种任务类型)。“Figure 1”,这个图放在摘要下面。

- 前提:使用GPT-4作为planner
- GUI grounding(“♣: ScreenSpot)” )、offline agent(“♠: Multimodal-Mind2Web, AndroidControl, and OmniACT” )、online agent benchmarks(“♥: Mind2Web-Live and AndroidWorld” )
- 结果是:
- UGround优于现有模型绝对值高达20%;
- 与额外使用文本输入的最先进agent相比,他们至少可以实现相当且通常更好的性能。
- 评估涵盖6大基准测试(3平台*3种任务类型)。“Figure 1”,这个图放在摘要下面。
method
先放一个图,然后是三部分内容。
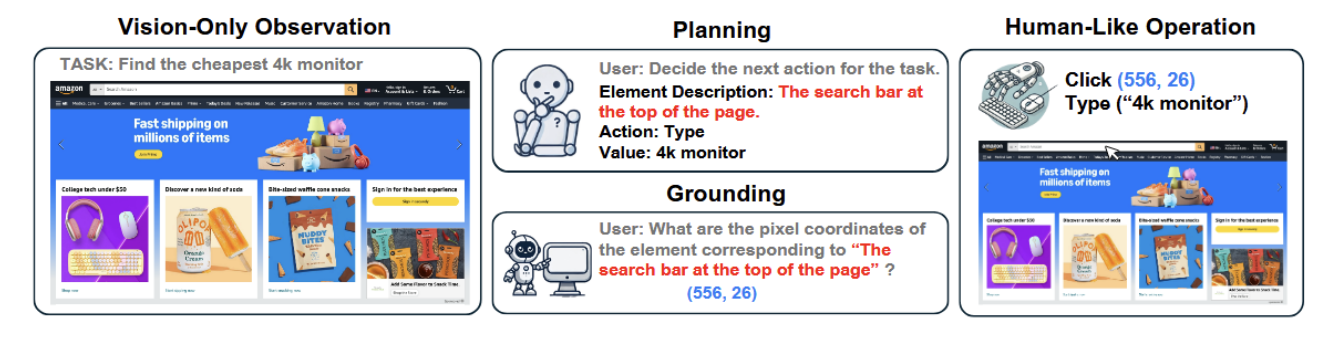
任务:找到最便宜的4k显示器。
Planning给出搜索栏在页面顶部,要搜索的是4k显示器。
Grounding给出用户需要的,搜索框的像素坐标,即(556,26)。
Human-Like Operation去对应的像素点输入”4k monitor”并执行click操作。
Overview:
- 他们采用流行的[[SeeAct]]框架,把他该进程仅对环境进行视觉观察+像素级操作,作为SeeAct-V。然后对比了一下原来的SeeAct和现在的SeeAct-V。
- 原来的SeeAct:
- planning和grounding都由MLLM处理,每一步都是MLLM先生成文本计划,然后选择grounding元素(都需要html或ally tree作为额外输入)。
- 现在的SeeAct-V:
- 仅输入屏幕截图,且grounding使用单独模型,由模型生成坐标。
- 原来的SeeAct:
- 引出需要一个强大的视觉基础模型。他们工作的主要技术贡献:一个recipe(包含data和modeling),用来训练此类通用视觉基础模型。
Data construction(简单的数据合成策略)
- “⟨screenshot, referring expression, coordinates⟩” 三元组作为训练数据
- 〈网页截图、指称表达(RE)、坐标〉
- 使用元素的中心点坐标作为预期输出
- 数据合成完全基于网页,他认为在web data上训练的模型完全可以推广到桌面和移动UI(由于GUI设计的相似性)
- 网页有结构化的数据,完整的html/dom
- 网页还有可视化渲染,即截图
- 浏览器能提供前两者的精细对应关系,即哪个html元素对应到截图里的哪个框
小标题:常见的RE类型([[RE]] is “referring expressions” )
前人的visual grounding works没有考虑多样性,所以他把RE分成三种类型。
- 视觉RE:视觉特征,如文本或图像的内容、形状、颜色
- 位置RE:包括绝对(页面的左上角)和相对(元素X的右侧)位置
- 功能RE:通过元件的功能指代元件,如导航至主页、前往我的购物车
小标题:来自Web的混合RE合成
翻译:提出一种混合合成的pipeline,为html元素生成不同的RE。(这里看不太懂),他把html属性及其可用属性输入到MLLM,并提示他生成不同的RE。这个过程产生将html属性与视觉特征相结合的复合RE或来自MLLM的新知识(如蓝鸟表示twitter)。 还用到LLM使生成的RE更加简洁。
- 混合的意思是即有规则又有LLM/MLLM的自由生成。
- 步骤:
- 步骤1:生成主描述
- 从html属性中抽取视觉和功能信息
- html属性可能不完整,用多模态大模型 LLaVA-NeXT-13B把截图和jhtml属性输入模型,提示生成REs
- 输出两类数据:
- 复合RE,能把html属性和视觉特征结合起来,如"空心爱心图标"
- 来自MLLM的新知识:如蓝鸟表示twitter,即使html没有这个信息
- 生成后用文本模型 Llama-3-8B-Instruct做精炼,让描述更简洁
- 随机选择之前两类数据中的一个,作为元素的主描述
- 步骤2:Positional Expressions(位置描述)
- 规则生成位置类RE,如”在页面顶部“,“在A和B之间”
- 规则生成语境类RE:
- 先识别控件类型,是单选框、复选框、输入框等
- 再根据DOM树层级,lable和input的关联,生成有语境的表达,如“标注为birthday的输入框”
- 数据来源和标注:
- 从[[Common Crawl]]汇集网页截图(横竖屏混合、不同分辨率)和元素元数据
- 步骤1:生成主描述
小标题:补充数据
之前有多个为Android构建基础数据的操作,所以他们合并了现有的数据集。还用GPT-4o来直接合成一小部分用于Web元素的RE
总结一下:
一个总计10M(1000万)个UI元素的数据集,其中90%来自混合合成管道。同一屏幕截图上的元素被批量处理以加速训练。
Model design
- 翻译:
- 采用开源模型架构:[[7B LLaVA-NeXT]]:视觉编码器+轻量投影+7B语言模型
- 输入输出公式:
- 任务统一成问答式指令:在这张截图中,描述{Description}对应的像素坐标是什么?
- 模型回答的是自然语言,但内容是精确的像素坐标
- Image Resolution:
- 挑战:
- GUI截图比自然图像大得多,早期LLaVA是为336px图像构建的,后来通过AnyRes技术放大到最多772px。然后介绍了AnyRes技术。
- 把大图像拆分成小切片,
- 用vision encoder独立编码每个切片,
- 每一行切片末尾添加token,帮助语言模型知道图像的“行”边界。所以AnyRes允许轻松扩展输入分辨率。但切片越多,训练/推理越慢。
- GUI截图比自然图像大得多,早期LLaVA是为336px图像构建的,后来通过AnyRes技术放大到最多772px。然后介绍了AnyRes技术。
- 他们的做法:
- 他们把允许的切片数量上限设为36个ViT切片
- 使用CLIP@224px作为image encoder来拆分,支持的最大分辨率达到
- 1,344 × 1,344 (landscape)
- 896 × 2,016 (portrait)
- 语言模型使用Vicuna-1.5-7b-16k,支持16K上下文长度,处理长视觉上下文。
- 常见的AnyRes会把“一张低分辨率的整图”与“高分辨率切片”融合,以提供全局语境。他们实测在 GUI 场景中,这个低分辨率整图(224px)几乎不提供有用的全局信息(小字和细控件看不清),还增加开销,因此干脆不使用该融合模块。
- 挑战:
- 总结:这一段主要说怎么把开源多模态模型框架改造成专门做GUI视觉定位的模型。他们用 LLaVA‑NeXT 7B 做 GUI 定位,把回答统一为自然语言里的“像素坐标”,通过 AnyRes 式的切片(最多 36 个、每块 224px)把大分辨率截图拆分编码,并用长上下文的 Vicuna 语言模型处理大量视觉token;同时剔除了低分辨率整图的融合,因为在 GUI 中对全局理解帮助不大。
experiments
- 先是一段总结(对比一般的研究是一两个基准的评估,他们更全面,用了6个基准),然后分5段。
- 三种评估:
- GUI视觉Grounding评估
- UGround视觉定位模型,能否把自然语言描述准确的落到截图的坐标上
- 感知能力评估,关注定位精度
- 缓存环境状态的离线代理评估
- 使用预先记录或缓存的截图与界面状态,不与真实环境交互
- 不包含真实交互的不确定性,如网络延迟、弹窗等
- 实时环境中的在线代理评估。
- 评估端到端的成功率,更真实
- GUI视觉Grounding评估
- 分两步,先看UGround的定位是否准,再看集成到他们的完整代理框架SeeAct-V后,端到端代理能否完成任务。
GUI VISUAL GROUNDING
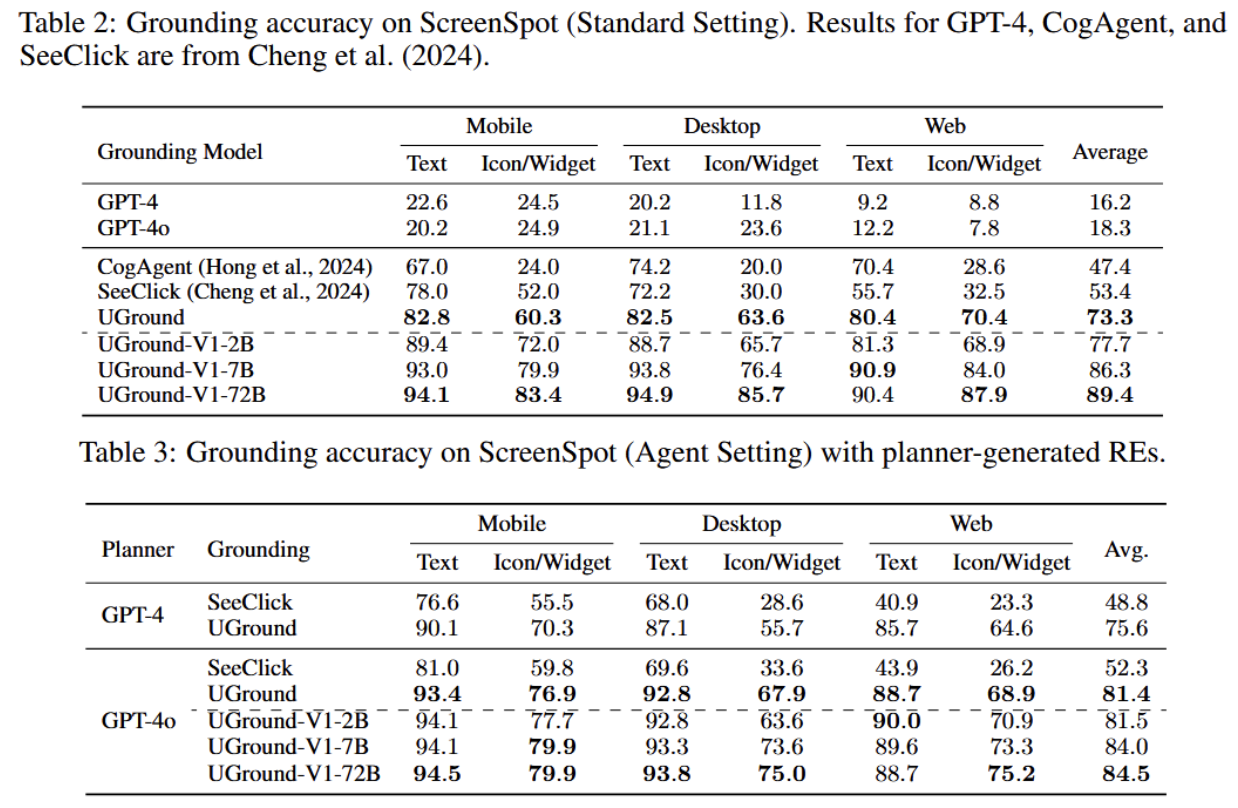
- ScreenSpot基准上评估UGround。这个基准测试专门为visual grounding on GUIs设计的。
- 1272个单步指令和目标元素的边界框(跨平台的)。
- 元素分类:基于文本的元素、图标(比如垃圾桶图标)、小部件(比如todo list)
- 评估基于两种settings:
- standard setting:
- ScreenSpot的标准设置,instruction是人写的,主要关注功能。比如一个叉叉表示关闭窗口的意思。
- 专注模型能否根据功能性描述准确定位到对应的界面元素。
- agent setting:
- 把每个ScreenSpot示例输入到MLLM,要求为目标元素生成不同的RE。
- standard setting:
- 对比模型
- UGround主要和SeeClick(ScreenSpot上最先进的视觉模型)(SOTA is state of the art)和CogAgent对比。
- 还有GPT-4、GPT-4o,展示通用模型在GUI grounding上的难度。
- 结果:两个表。
- 在ScreenSpot基准上,UGround表现很好。两种settings都提升很多。尽管从未在桌面UI上训练,但在桌面UI上表现突出。在图标和小部件上表现尤其出色。
- 在ScreenSpot基准上,UGround表现很好。两种settings都提升很多。尽管从未在桌面UI上训练,但在桌面UI上表现突出。在图标和小部件上表现尤其出色。
OFFLINE AGENT EVALUATION
- 总体思路:用事先缓存好的环境状态和金标准轨迹来评测代理。
- 分Web/Mobile/Desktop。
- Web:
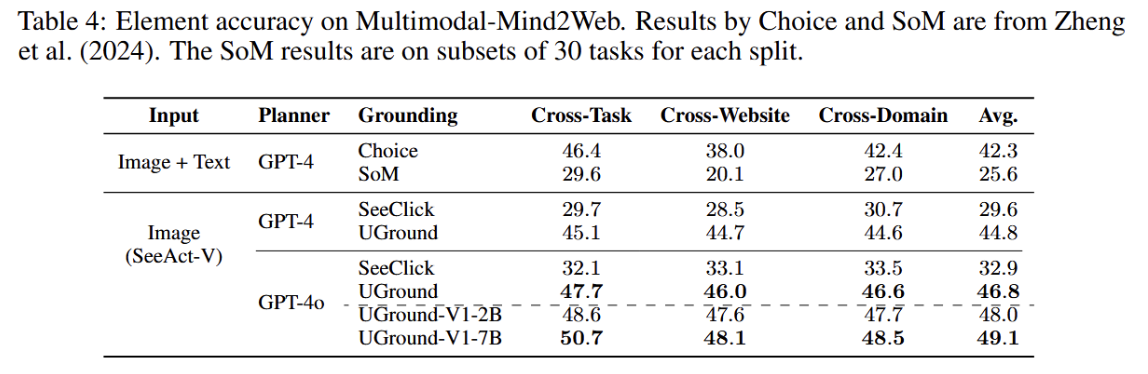
- Mind2Web的多模态扩展:Multimodal-Mind2Web,用来评估web task。
- 测试集有1013个task,覆盖100+website。
- 每个task提供高层指令、逐步动作序列,以及每步动作前的网页截图,所有沿着金标准轨迹的网页都已缓存,便于离线评测。
- 使用元素准确率作为指标
- 对比Grounding的基线策略:都依赖文本或结构表示
- 基于html的Choice:先用html过滤出候选元素,再让规划模型从中选择
- SoM策略(Set-of-Mark):在截图上覆盖标签编号,再让规划模型从标签中选
- 测试集有1013个task,覆盖100+website。
- 结论:
- SeeAct-V仅使用视觉输入,元素准确率由于所有依赖html的基线方法
- Mind2Web的多模态扩展:Multimodal-Mind2Web,用来评估web task。
- Mobile:
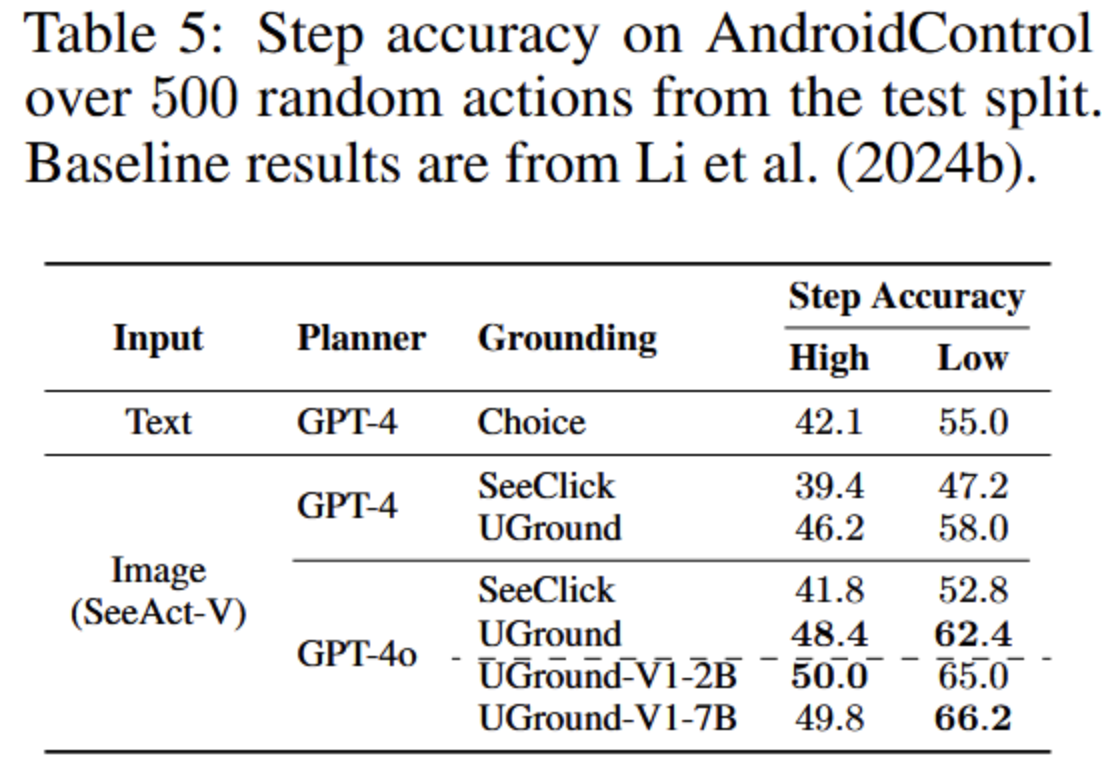
- 使用AndroidControl数据集
- 833个App上的15K个任务
- 高级/低级两种任务
- 高级任务只给意图
- 低级任务给意图+每步对应的低层具体指令
- 使用逐步准确率作为指标
- 对比基线
- 基于ally树的M3A文本变体:用 GPT-4 生成文本动作并从 a11y 树中选择元素(Choice 式选择)。
- 结论:
- 高级/低级任务中都优于文本基线方法
- 低级任务中表现尤其出色
- 使用AndroidControl数据集
- Desktop:
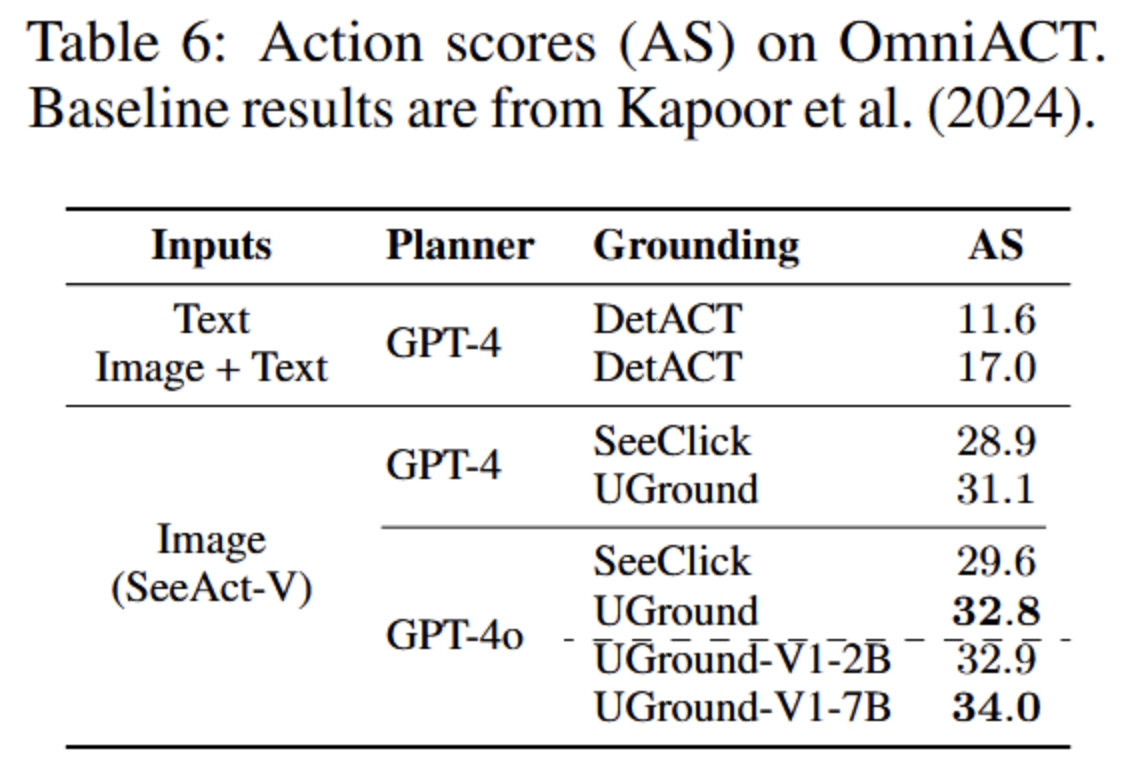
- OmniACT
- 38个桌面应用和27个网站的9802个任务,跨操作系统
- 使用动作分数作为指标
- 对比基线
- DetACT方法:
- 通过OCR、图标匹配和颜色检测提取UI元素和坐标
- 按任务相关性过滤
- 再交给LLM/MLLM生成含有正确坐标的PyAutoGUI脚本
- DetACT方法:
- 他们的方法(SeeAct-V+UGround):
- 只用原始截图作为输入,不用OCR/HTML/ally树等
- 让MLLM先生成元素描述,再用UGround把描述转化成坐标,最后填入PyAutoGUI脚本
- 为了公平,严格复用DetACT的提示词和检索策略
- 结论:
- 动作分数上优于DetACT
- 证明了仅凭视觉输入可以处理复杂桌面应用
- OmniACT
- Web:
ONLINE AGENT EVALUATION
- 在真实环境中评估,成本较高,只使用UGround作为grouding模块。
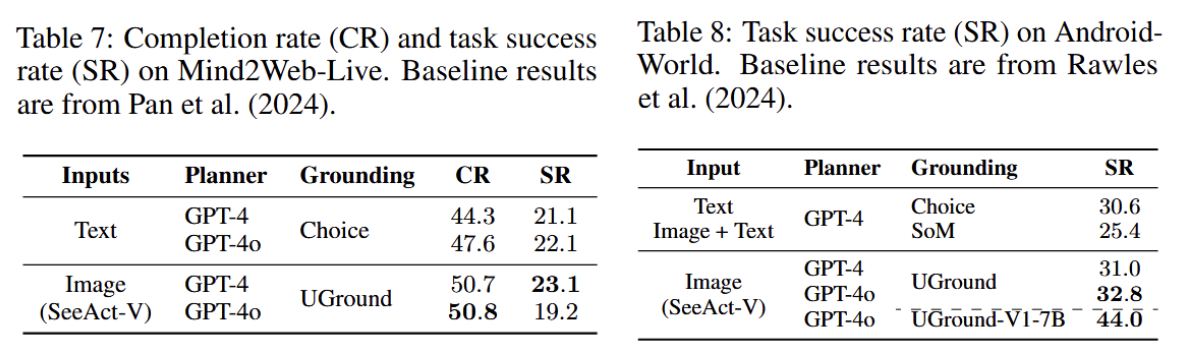
- Web:Mind2Web-Live
- 基于Mind2Web添加功能评估
- 对比基线:
- 来自Pan et al. (2024) is text-only,主要基于 HTML 结构感知和交互,一次处理上百个 HTML 元素。
- 关键机制:
- 为每个任务标注关键节点(key nodes)。无论代理采取何种路径,只要完成这些关键节点就可判定任务进展或成功。
- 指标:
- 微完成率(micro completion rate):跨所有任务计算,完成的关键节点占比。
- 任务成功率(task success rate):完全完成所有关键节点的任务比例。
- 结论:
- 微观完成率和任务成功率达到或优于使用html元素的基线
- 证明视觉输入足以完成实际的Web任务
- Mobile:AndroidWorld
- 20个应用中的116个任务
- 使用任务成功率作为指标
- 对比基线:SOTA 代理M3A及其SoM变体,Rawles et al. (2024)
- M3A 接收“原始截图 + SoM 标注图 + 文本化的 UI 元素”,或仅“文本化 UI 元素”(文本-only 版)作为观察。
- 决策方式:采用 ReAct 风格推理,从 UI 元素列表中选择下一目标元素;并加入自反(self-reflection)来总结当前动作、提升后续决策。
- SoM(Set-of-Mark):在截图上叠加编号标记,方便模型从标记里选元素。
- 结论:
- 任务成功率优于M3A的SoM变体
- 尽管AndroidUI通常更适合SoM方法,但视觉输入仍表现出色
ERROR ANALYSIS
对失败案例分析,结论是规划错误是主要的失败原因(60%-70%),并不是grounding错误,表示UGround的grounding能力很强。
常见的规划错误:生成错误元素的描述、产生不存在的元素、过于模糊的描述。
grounding错误主要源于长尾图标的特殊语义,难以捕捉。比如特定应用中的自定义图标。
在实际agent任务中,由于头部元素(?)占主导,UGround表现相对稳健。
conclusions and limitations
结论:
- GUI agent框架 SeeAct-V
- GUI agent应该完全通过视觉感知+像素级操作,而非依赖html和ally树等文本表示。
- 框架设计上:
- 模块化架构:分离规划和视觉定位。通过MLLM生成文本计划作为规划,再用专用模型生成坐标作为视觉定位。灵活可扩展。
- 纯视觉输入:仅使用截图作为环境感知,消除文本表示的噪声、不完整和计算开销。
- 构建通用视觉定位模型UGround
- 数据创新:
- Web-Hybrid,网页合成数据,生成最大规模的GUI视觉定位数据集(1300万张截图,1000万UI元素)。覆盖多样化的指代表达式REs。(视觉、位置、功能REs)
- 融合现有的Android数据集和GPT-4生成的开放性REs。
- 模型创新:
- 基于LLaVA-NeXT-7B架构,适配高分辨率输入(最高1344*1344)
- 输出格式:直接生成像素坐标
- 数据创新:
- 多平台实验验证
- 视觉定位任务:
- UGround在标准设置和代理设置下均显著超越SOTA模型(如SeeClick),平均提升20%-29%。
- 跨平台泛化:在桌面端(未训练数据)和移动端均表现优异,尤其擅长图标和小部件定位。
- 端到端代理任务:
- 离线评估(Web/Mobile/Desktop):
- SeeAct-V在Multimodal-Mind2Web、AndroidControl、OmniACT上均优于依赖文本输入的SOTA方法。
- 在线评估(Mind2Web-Live/AndroidWorld):
- 任务成功率与基线相当或更高,证明视觉代理的实用性。
- 离线评估(Web/Mobile/Desktop):
- 视觉定位任务:
局限
数据效率问题
- 训练数据基于网页合成,存在元素重复率高的问题(如常见按钮/链接)。未来可通过数据去重和分组提升训练效率。
长尾语义泛化不足
- 模型难以捕捉长尾图标的特殊语义(如应用特有的自定义图标),导致部分定位错误。
- 解决方向:需结合文档学习或针对性探索长尾元素。
桌面UI数据稀缺
- UGround未在桌面UI数据上训练,虽实验显示跨平台泛化能力,但桌面UI(如macOS/Windows)的特定设计仍需更多数据支持。
模块化设计的定位
- UGround是专用定位模块,需依赖外部规划器(如MLLM)生成计划。未来可探索端到端模型,但需解决训练数据获取成本高的问题。
未来工作方向
- 提升数据质量与效率
- 开发更智能的数据去重策略,减少合成数据的冗余。
- 解决长尾问题
- 结合领域知识或用户反馈增强模型对特殊图标的理解。
- 构建桌面UI数据集
- 收集多样化桌面环境数据,提升模型在桌面任务中的鲁棒性。
- 推动端到端模型发展
- 探索将定位能力整合到单一模型中,但需平衡训练成本与效果。
关键意义
- 实践价值:SeeAct-V证明了纯视觉代理的可行性,为跨平台GUI自动化提供新范式。
- 理论贡献:强调模块化设计在复杂环境中的优势,定位模块可独立优化并适配不同规划器。
- 数据资源:公开最大规模GUI视觉定位数据集和模型([GitHub链接]),推动领域发展。